What kind of software business can you build today?
I took a couple of months “off” before joining Honeycomb — spent mostly doing go to market consulting work for pre-launch startups and talking to people about what’s interesting, clocking 2–5 meetings a day.
Exhausting. Interesting.
TL;DR
You can either build a marketplace or be vertically integrated.
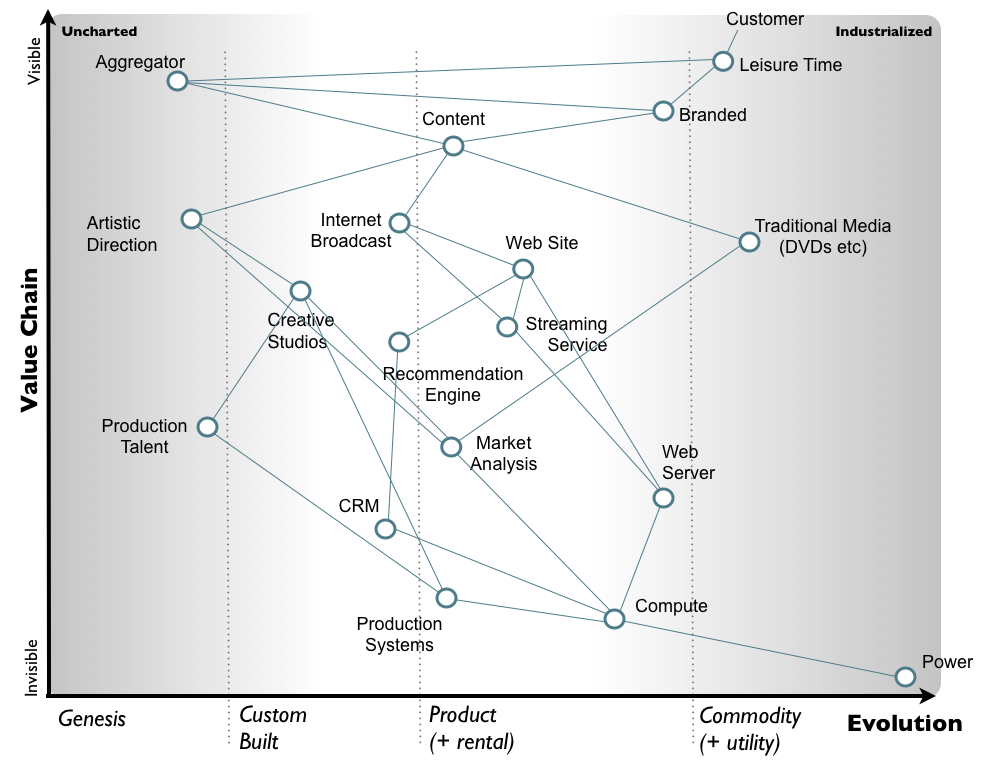
What you cannot do is build a platform, unless it’s for some completely un[der]served market.
Platform plays are hard
This should be a truism. How do you compete with Amazon, Google, or even Twilio? If we take them on head on, we lose. There’s nothing you’re going to build that they can’t copy. Witness the snap-ification of all Facebook properties.
Users who come to you first, an entirely new generation, may stay with you. But the vast population using an existing platform will prefer to use that platform’s copy of your feature because the value to them generated by the network effects (and their own personal investment) of the incumbent platform is not worth abandoning to start from scratch on your thing.
Platforms tend to be subject to winner-take-most-if-not-all dynamics and you have to find somewhere where a winner has not already taken the most.
Thus un[der]served markets. It seems there’s plenty of space to build non-generic platforms for specific markets with their own needs, language, culture, and particularities. Of course that’s TAM limiting — and unless there are premiums to be charged (high relative margins) — maybe not fit for venture capital.
Be vertically integrated
Instead of building wide, build deep. Although I think this applies more to existing software businesses rather than someone building something new. Unless it’s in an unserved niche, in which case maybe you can build deep before attracting too much attention from outside the market you choose to operate in.
If you look at Salesforce’s acquisitions, ignoring the usual failed forays, what stands out is that they are going deep in go to market. They’re buying up bits of the funnel, including customer success/support for the world of MRR/ARR driven GTM machines.
Build (or modernize) marketplaces
Connect supply and demand that haven’t been connected before, or electro-internet-connectify a marketplace that’s still run off paper-faxes-and-phone-calls. Usually in the process you’ll either become a new (hopefully) value-adding intermediary or disintermediate incumbent rent-seekers.
See Haven and Grand Rounds.
What is the critical differentiator for incumbents, and can some aspect of that differentiator be digitized? If that differentiator is digitized, competition shifts to the user experience, which gives a significant advantage to new entrants built around the proper incentives Companies that win the user experience can generate a virtuous cycle where their ownership of consumers/users attracts suppliers which improves the user experience— Aggregation Theory by Ben Thompson